

Projects
Munich Rental Guide
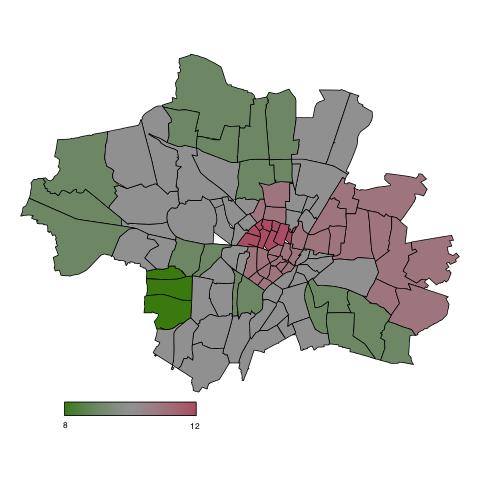
The Munich rental guide gives an overview of rents for flats in Munich and represents the local mean level of paid rents. The statistical model of the Munich rental guide 2015 is based on a representative sample with over 3000 flats in Munich. To model the mean level of rents in Munich with respect to the size, type, location, facilities and qualitiy of the flats we used a weighted general additive model. To get the upper and lower bounds of usually paid rents in Munich we used quantile regression models. As part of this project we developed the statistical model and - in cooperation with a computer scientist - a user-friendly online version of the Munich rental guide.
Coordinator(s): Prof. Dr. Goeran Kauermann, Dr. Michael Windmann
Model based optimization for survival analysis across different cohorts and stable feature selection
The aim is to develop new statistical methods that allows model selection across different cohorts with stable feature selection for survival analysis. The number of prediction methods for survival analysis based on high dimensional clinical data is large. The best model often depends on the cohort that was used. To find the best model for single cohorts efficiently and with a considerably reduced runtime, modern methods for model-based optimization can be used. In this project, we try to find models that generalize better across cohorts, i.e., models that yield a good prediction for different cohorts and, at the same time, provide a stable feature selection. The model that is found using this multiple criteria must be compared with other models that were found for a specific cohort in order to assess the quality loss because of the additional stability criteria. The reproducibility can be improved by embedding the results in free and openly accessible experiment-databases because comparison studies of prediction methods are reproducible and can be transparently and collaboratively extended.
Coordinator(s): Prof. Dr. Jörg Rahnenführer, Prof. Dr. Bernd Bischl
Staff: Xudong Sun
International Trade of Arms: A Network Approach
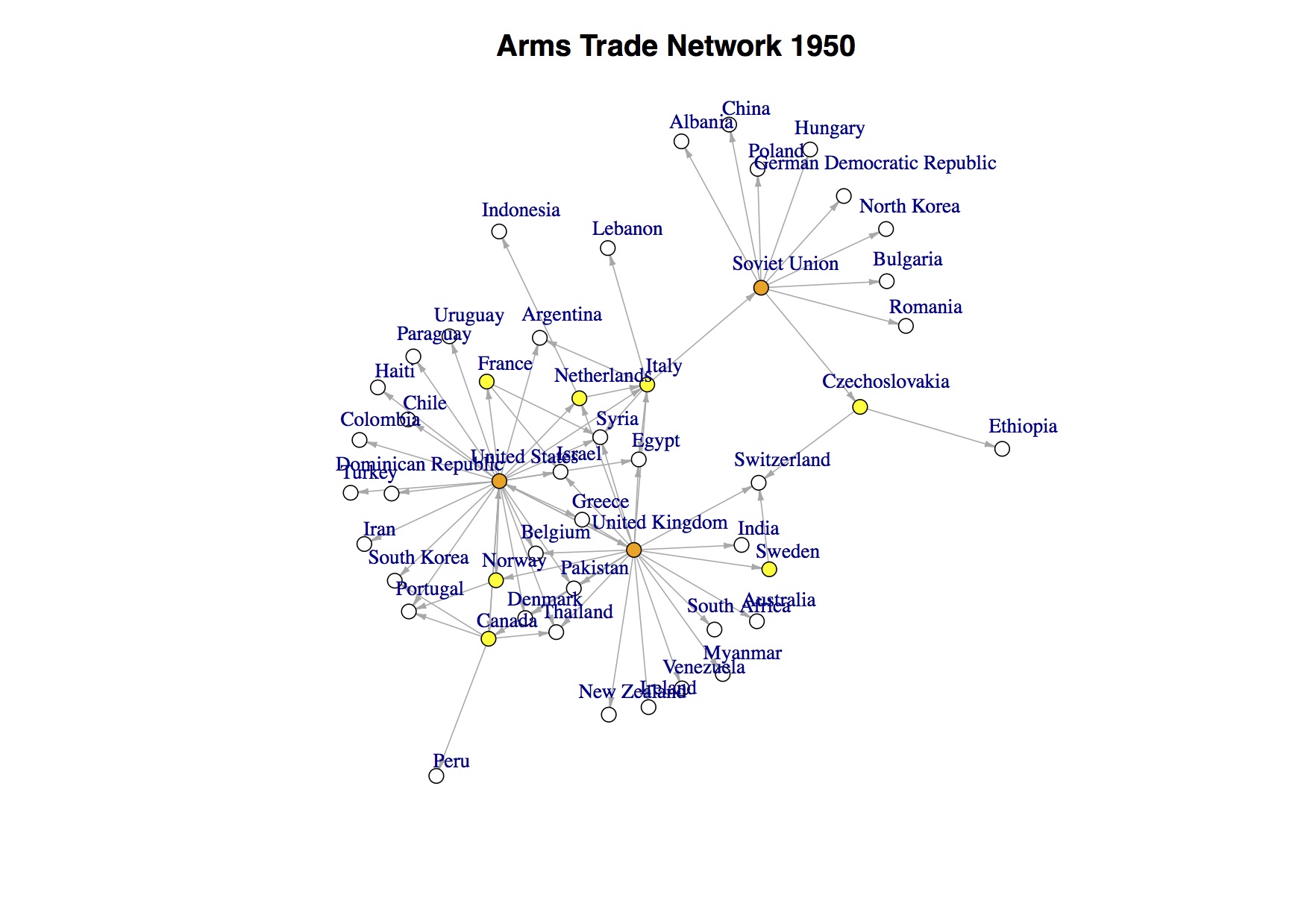
The project proposes a network perspective for the empirical analysis of the international trade of arms. The quantitatively-oriented network approach is based on measurements of the export, transfer, and import of arms over long time periods 1960-2010). Within the project we will analyze major conventional weapons (MCW) and small arms and light weapons (SALW) and test popular conjectures according to which the structure of trade in MCW follows to a higher degree political motivations whereas SALW is expected to be rather economically-oriented. The complexity of the underlying data sources requires the development of new inferential statistical techniques for the modeling of valued (i.e.: non-binary) networks.
Coordinator(s): Prof. Dr. Paul Thurner, Prof. Dr. Göran Kauermann
Staff: Michael Lebacher, Christian Schmid, Eva Ziegler
Implementation and Evaluation of Methods for Automatic, Massively Parallel Model Selection in Machine Learning
For challenging prediction problems in areas like medical diagnosis, text or image recognition, non-parametric machine learning methods including deep neural networks, support vector machines, boosting methods or random forests are typically used. These models are able to make highly accurate predictions, but their runtime does not scale well with increasing number of data points. For a given prediction problem, it is often unclear which modeling approach is optimal. Parallelization is one obvious way to reduce the required time for computing on large datasets. Complex configurations should be optimized by intelligent methods. Because of the high computational costs of these models, only black-box-optimizers with the capability to handle strongly restricted budget of evaluations can be used.
For a given large-scale dataset the optimal model should be selected based on a large space of potential methods, preprocessing options and algorithmic settings. To achieve this, modern and efficient optimizers like Iterated-Racing and MBO should be used in highly parallelel versions, which will be implemented and evaluated in this project. The aim is a highly parallel, fully automatic model selection engine, which runs on the LRZ HPC systems.
Coordinator(s): Prof. Dr. Bernd Bischl
Stuff: Janek Thomas
Differential Item Functioning in Item Response Models - New Estimation Procedures and Diagnostic Tools
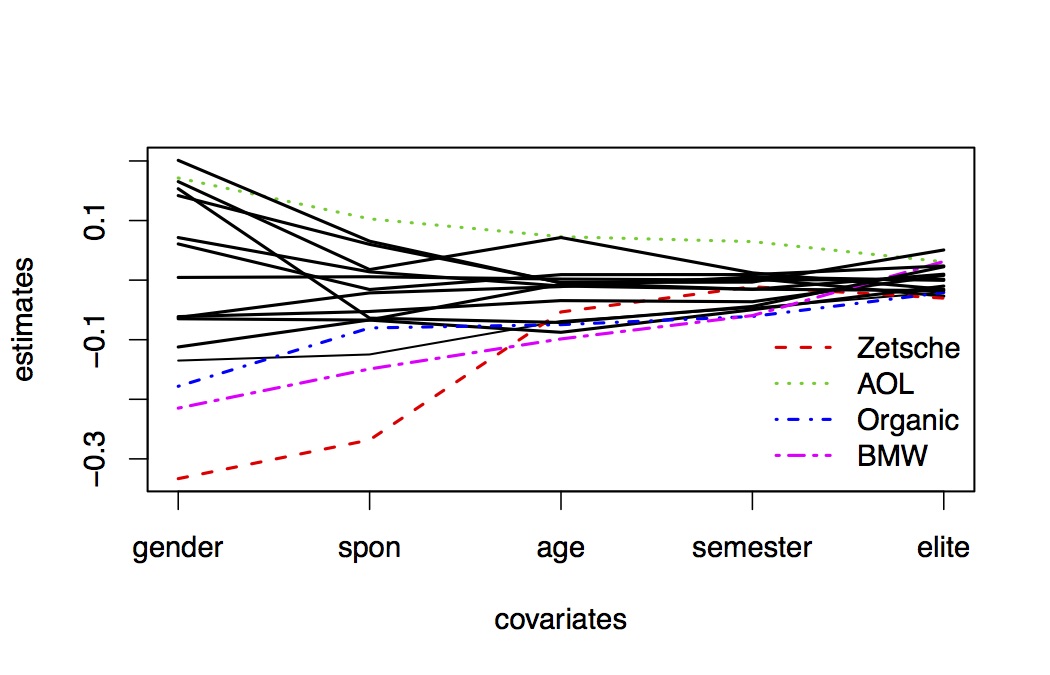
The project deals with the phenomenon of Differential Item Functioning (DIF). Assessment tests suffer from DIF if for subjects with equal abilities (for example intelligence) the probabilities of a correct response differ in subgroups. DIF can be caused by characteristics of the subjects or persons like, for example, gender, age or different social or cultural backgrounds. DIF-items can lead to biased estimates and, therefore, the detection of DIF-items is an important issue in the development of valid psychological tests. The objective of the project is to develop regularization techniques that are able to identify DIF-items in general item response models.
Coordinator(s): Prof. Dr. Gerhard Tutz
Staff: Dr. Gunther Schauberger
Quantitative and Computational Systems Science Center (QCSSC)

The Quantitative and Computational Systems Science Center (QCSSC), which was established in 2014 under the LMUexcellent programme, is a forum for intensive interdisciplinary cooperation between researchers from various academic disciplines. The main aim of the QCSSC is to foster both existing and new collaborations between researchers from quantitative and computational research fields (mathematics, informatics, and statistics) with scientists from various other research areas (e.g. biochemistry, bioinformatics, physics, economics and finance, linguistics, philosophy) at the LMU in order to enhance an exchange between theory/methodology and data/application. The Center provides an ideal environment for interdisciplinary seminars, workshops, conferences, study programs, networks, and research projects.
Coordinator(s): Prof. Dr. Goeran Kauermann, Prof. Dr. Sonja Greven